软件构造知识点总结 - 3
第一节 可复用性的度量、形态和外部观察
什么是软件复用
- 软件复用是使用现有软件组件实施或更新软件系统的过程。
- 软件复用的两个观点:
- 面向复用编程(programming for reuse):开发出可复用的软件
- 开发成本高于一般软件的成本:要有足够高的适应性
- 性能差些: 针对更普适场景,缺少足够的针对性
- 基于复用编程(programming with reuse):利用已有的可复用软件搭建应用系统
- 可复用软件库,对其进行有效的管理
- 往往无法拿来就用,需要适配
- 面向复用编程(programming for reuse):开发出可复用的软件
- 为什么需要复用:
- 复用降低成本和开发时间
- 复用的代码经过充分测试,可靠、稳定
- 产出标准化,在不同应用中保持一致
软件复用的代价:
- 软件可复用的部分需要设计在如下的标准上:明确的定义、开放的方法、简洁的交互规范、可理解的文档,并着眼于未来。
- 不仅program for reuse代价高,program with reuse代价也高
代码复用的类型:
- 白盒复用:源代码可见,可修改和扩展
- 含义:复制已有代码到正在开发的系统,进行修改
- 优点:可订制化程度高
- 缺点:对其修改增加了软件的复杂度,且需要对其内部充分的了解
- 黑盒服用:源代码不可见,不能修改
- 含义:只能通过过API接口来使用,无法修改代码
- 优点:清晰、简单
- 缺点:适用性差
- 白盒复用:源代码可见,可修改和扩展
高复用性的软件应具有如下特性:
- 小、简单
- 与标准兼容
- 灵活可变
- 可扩展
- 泛型、参数化
- 模块化
- 变化的局部性
- 稳定
- 丰富的文档和帮助
可复用实现的级别
源代码级别的复用
模块级别的复用:类、抽象类、接口
- 复用类:
- 源码并非是必要的,可能只需要类文件或jar
- 只需要将这个类加入到类路径
- 可以使用工具javap获得一个类的
public方法
- 使用复用类的注意事项:
- 文档十分重要
- 压缩会有助于复用
- 管理更少的代码
- 版本兼容性
- 需要和类相关的包
- 复用类的方法:继承和委派
- 继承(Inheritance):
- 类扩展了现有类的属性/行为;
- 另外,他们可能会
Override现有的行为; - 通常需要在实施之前设计继承层次结构;
- 委派(Delegation):
- 根本没有父子关系的类中使用继承是不合理的,可以用委派的方式来代替。
- 委托是简单的将一个对象连接到另一个对象上,使另一个对象获得这个对象方法的子集(一个实体将某个事物传递给另一个实体)。
- 明确的委托:明确将需要传的对象传到目标对象上
- 含蓄的委托:委托可以被描述为一种共享代码数据的低级别机制
- 委派的类型:
- Use(A uses B)
- Composition/aggregation (A owns B)
- Association (A has B)
- 继承(Inheritance):
库级别的复用:API/包
- 方法:Libaray、framework
- library:
- 库定义:一组提供可重用功能的类和方法(API)
- 开发者构造可运行软件实体,其中涉及到对可复用库的调用
- Java中有很多的库可以复用,例如Guava:Google的Java核心库;Apache Commons等
- framework:
- 框架定义:一组具体类、抽象类、及其之间的连接关系
- 作为主程序加以执行,执行过程中调用开发者所写的程序
- 开发者根据 framework的规约,填充自己的代码进去,形成完整系统
- library:
系统级别的复用:框架
将framework看作是更大规模的API复用,除了提供可复用的API,还将这 些模块之间的关系都确定下来,形成了整体应用的领域复用。开发者的任务就是增加新代码、对抽象类进行具体化。展开来说就是以下几点:
- 通常通过选择性覆盖来扩展框架; 或者程序员可以添加专门的用户代码来提供特定的功能—定义继承了抽象类祖先操作的具体类
- 设计模式(Hook方法),它被应用程序覆盖以扩展框架。 Hook方法系统地将应用程序域的接口和行为与应用程序在特定上下文中所需的变体解耦。
- 控制反转,由第三方的容器来控制对象之间的依赖关系,而非传统实现中由代码直接操控。由第三方的容器来控制对象之间的依赖关系,而非传统实现中由代码直接操控。
- 不可修改的框架代码:在接受用户实现的扩展时,框架代码不应该被修改。 换句话说,用户可以扩展框架,但不应修改其代码。
对可复用性的外部观察
Type Variation 类型可变
- 能够复用的部分应该类型参数化,以适应不同的数据类型
- 复用的部分应该一般化
- 适应不同的类型,且满足LSP
Implementation Variation 实现可变
- ADT 有多种不同的实现,提供不同的representations 和abstract function ,但具有同样的specification (pre-condition, post-condition, invariants) ,从而可以适应不同的应用场景
- Routine Grouping 功能分组
- 提供完备的细粒度操作,保证功能的完整性,不同场景下复用不同的操作( 及其组合)
Representation Independence 表示独立
- 内部实现可能会经常变化,但客户端不应受到影响。
Factoring Out Common Behaviors 共性抽取
- 将共同的行为(共性)抽象出来,形成可复用实体
白盒框架和黑盒框架
框架也可分为白盒框架和黑盒框架两类。
- 白盒框架:
- 通过继承和动态绑定实现可扩展性。
- 通过继承框架基类并重写预定义的hook方法来扩展现有功能。
- 通常使用模板方法模式等设计模式来覆盖hook方法。
- 黑盒框架:
- 通过为可插入框架的组件定义接口来实现可扩展性。
- 通过定义符合特定接口的组件来复用现有功能。
- 这些组件通过委派(Delegation)与框架集成。
第二节 设计可复用的软件
设计可复用的类——LSP
- 在OOP之中设计可复用的类
- 封装和信息隐藏
- 继承和重写
- 多态、子类和重载
- 泛型编程
- LSP原则
- 委派和组合(Composition)
行为子结构
子类型多态( Subtype polymorphism):客户端可用统一的方式处理不同类型的对象 。
examples
1
2
3Animal a = new Animal();
Animal c1 = new Cat();
Cat c2 = new Cat();在可以使用
a的场景,都可以用c1和c2代替而不会有任何问题。在java的静态类型检查之中,编译器强调了几条规则:
- 子类型可以增加方法,但不可删
- 子类型需要实现抽象类型中的所有未实现方法
- 子类型中重写的方法必须有相同或子类型的返回值
- 子类型中重写的方法必须使用同样类型的参数
- 子类型中重写的方法不能抛出额外的异常
行为子结构也适用于指定的方法:
- 更强的不变量
- 更弱的前置条件
- 更强的后置条件
逆变与协变
逆变与协变综述:如果A、B表示类型,f(⋅)表示类型转换,≤表示继承关系(比如,$A≤B$表示A是由B派生出来的子类):
- f(⋅)是逆变(contravariant)的,当$A \le B$时有$f(B) \le f(A)$成立;
- f(⋅)是协变(covariant)的,当$A \le B$时有$f(A) \le f(B)$成立;
- f(⋅)是不变(invariant)的,当$A \le B$时上述两个式子均不成立,即f(A)与f(B)相互之间没有继承关系。
协变(Co-variance):
- 父类型$\to$子类型:越来越具体(specific)。
- 在LSP中,返回值和异常的类型:不变或变得更具体 。
- examples

- 逆变(Contra-variance):
- 父类型$\to$子类型:越来越抽象。
- 参数类型:要相反的变化,不变或越来越抽象。
- examples

这在Java中是不允许的,因为它会使重载规则复杂化。
Liskov替换原则(LSP)
- 里氏替换原则的主要作用就是规范继承时子类的一些书写规则。其主要目的就是保持父类方法不被覆盖。
- 含义:
- 子类必须完全实现父类的方法
- 子类可以有自己的个性
- 覆盖或实现父类的方法时输入参数可以被放大
- 覆盖或实现父类的方法时输出结果可以被缩小
- LSP是子类型关系的一个特殊定义,称为(强)行为子类型化。在编程语言中,LSP依赖于以下限制:
- 前置条件不能强化
- 后置条件不能弱化
- 不变量要保持或增强
- 子类型方法参数:逆变
- 子类型方法的返回值:协变
- 异常类型:协变
各种应用中的LSP
数组是协变的
- 数组是协变的:一个数组
T[],可能包含了T类型的实例或者T的任何子类型的实例 - 即子类型的数组可以赋予父类型的数组进行使用,但数组的类型实际为子类型。
泛型中的LSP
- Java中泛型是不变的,但可以通过通配符”?”实现协变和逆变:
<? extends>实现了泛型的协变:List<? extends Number> list = new ArrayList<Integer>();<? super>实现了泛型的逆变:List<? super Number> list = new ArrayList<Object>();
- 由于泛型的协变只能规定类的上界,逆变只能规定下界,使用时需要遵循PECS(producer–extends, consumer-super):
- 要从泛型类取数据时,用extends;
- 要往泛型类写数据时,用super;
- 既要取又要写,就不用通配符(即extends与super都不用)。
- 泛型是类型不变的(泛型不是协变的)。举例来说
ArrayList<String>是List<String>的子类型List<String>不是List<Object>的子类型
- 在代码的编译完成之后,泛型的类型信息就会被编译器擦除。因此,这些类型信息并不能在运行阶段时被获得。这一过程称之为类型擦除(type erasure)。
- 类型擦除的详细定义:如果类型参数没有限制,则用它们的边界或Object来替换泛型类型中的所有类型参数。因此,产生的字节码只包含普通的类、接口和方法。
- 类型擦除的结果:
<T>被擦除T变成了Object
Wildcards(通配符)
- 无界通配符类型使用通配符(
?)指定,例如List<?>,这被称为未知类型的列表。 - 在两种情况下,无界通配符是一种有用的方法:
- 如果您正在编写可使用Object类中提供的功能实现的方法。
- 当代码使用泛型类中不依赖于类型参数的方法时。 例如
List.size或List.clear。 事实上,Class<?>经常被使用,因为Class<T>中的大多数方法不依赖于T。
examples
1 | public static void printList(List<Object> list) { |
printList的目标是打印任何类型的列表,但它无法实现该目标 ,它仅打印Object实例列表; 它不能打印List <Integer>,List <String>,List <Double>等,因为它们不是List <Object>的子类型。
- 要编写通用的
printList方法,请使用List<?> - 低边界通配符
<? super A> e.g. List<? super Integer> List<Number> - 上边界通配符
<? extends A> e.g. List<? extends Number> List<Integer>
1 | public static void printList(List<?> list) { |
委派与组合
委派(Delegation)
委派/委托:一个对象请求另一个对象的功能 。
委派是复用的一种常见形式。
分为显性委派:将发送对象传递给接收对象;
以及隐性委派:由语言的成员查找规则。
委派设计模式:是一种用来实现委派的软件设计模式;
委派依赖于动态绑定,因为它要求给定的方法调用可以在运行时调用不同的代码段;
委派的过程如下:

Receiver对象将操作委托给Delegate对象,同时Receiver对象确保客户端不会滥用委托对象;
委派与继承
- 继承:通过新操作扩展基类或覆盖操作。
- 委托:捕获操作并将其发送给另一个对象。
- 许多设计模式使用继承和委派的组合。
- Problem:如果子类只需要复用父类中的一小部分方法,
- Solution:可以不需要使用继承,而是通过委派机制来实现。
- 本质上,一个类不需要继承另一个类的全部方法,通过委托机制调用部分方法。
复合继承原则(CRP)
复合复用原则(CRP):类应当通过它们之间的组合(通过包含其它类的实例来实现期望的功能)达到多态表现和代码复用,而不仅仅是从基础类或父类继承。
我们可以将组合(Composition)理解为(has a)而继承理解为(is a);
委派可以看做Object层面的复用机制,而继承可以看做是类的层面;
只需针对不同子类的对象,委派能够计算该子类的奖金的方法的BonusCalculator。这样一来就不需要在子类继承的时候进行重写。
总结:组合来代替继承的更普遍实现:
- 用接口来实现系统的最基础行为
- 接口之间用extends来实现系统功能的扩展(接口组合)
- 类implements 组合接口
委派的类型
临时性委派(Dependency):最简单的方法,调用类里的方法(use a),其中一个类使用另一个类而不实际地将其作为属性。

永久性委派(Association):类之中有其它类的具体实例来作为一个变量(has a)

- 更强的委派,组合(Composition):更强的委派。将一些简单的对象组合成一个更为复杂的对象。(is part of)!
- 聚合(Aggregation):对象是在类的外部生成的,然后作为一个参数传入到类的内部构造器。(has a)

组合与聚合
在组合中,当拥有的对象被破坏时,被包含的对象也被破坏。在聚合中,这不一定是真的。以生活中的事物为例:大学拥有多个部门,每个部门都有一批教授。 如果大学关闭,部门将不复存在,但这些部门的教授将继续存在。 一位教授可以在一个以上的部门工作,但一个部门不能成为多个大学的一部分。大学与部门之间的关系即为组合,而部分与教授之间的关系为聚合。
设计可复用库与框架
之所以library和framework被称为系统层面的复用,是因为它们不仅定义了1个可复用的接口/类,而是将某个完整系统中的所有可复用的接口/类都实现出来,并且定义了这些类之间的交互关系、调用关系,从而形成了系统整体 的“架构”。
- 相应术语:
- API(Application Programming Interface):库或框架的接口
- Client(客户端):使用API的代码
- Plugin(插件):客户端定制框架的代码
- Extension Point:框架内预留的“空白”,开发者开发出符合接口要求的代码( 即plugin) , 框架可调用,从而相当于开发者扩展了框架的功能
- Protocol(协议):API与客户端之间预期的交互序列。
- Callback(反馈):框架将调用的插件方法来访问定制的功能。
- Lifecycle method:根据协议和插件的状态,按顺序调用的回调方法。
API和库
- 建议:始终以开发API的标准面对任何开发任务;面向“复用”编程而不是面向“应用”编程。
- 难度:要有足够良好的设计,一旦发布就无法再自由改变。
- 编写一个API需要考虑以下方面:
- API应该做一件事,且做得很好
- API应该尽可能小,但不能太小
- Implementation不应该影响API
- 记录文档很重要
- 考虑性能后果
- API必须与平台和平共存
- 类的设计:尽量减少可变性,遵循LSP原则
- 方法的设计:不要让客户做任何模块可以做的事情,及时报错
框架
框架(Framework)是整个或部分系统的可重用设计,表现为一组抽象构件及构件实例间交互的方法;另一种定义认为,框架是可被应用开发者定制的应用骨架。前者是从应用方面而后者是从目的方面给出的定义。
为了增加代码的复用性,可以使用委派和继承机制。同时,在使用这两种机制增加代码复用的过程中,我们也相应地在不同的类之间增加了关系(委派或继承关系)。而对于一个项目而言,各个不同类之间的依赖关系就可以看做为一个框架。一个大规模的项目可能由许多不同的框架组合而成。
框架与设计模式:
- 框架、设计模式这两个概念总容易被混淆,其实它们之间还是有区别的。构件通常是代码重用,而设计模式是设计重用,框架则介于两者之间,部分代码重用,部分设计重用,有时分析也可重用。在软件生产中有三种级别的重用:内部重用,即在同一应用中能公共使用的抽象块;代码重用,即将通用模块组合成库或工具集,以便在多个应用和领域都能使用;应用框架的重用,即为专用领域提供通用的或现成的基础结构,以获得最高级别的重用性。
- 框架与设计模式虽然相似,但却有着根本的不同。设计模式是对在某种环境中反复出现的问题以及解决该问题的方案的描述,它比框架更抽象;框架可以用代码表示,也能直接执行或复用,而对模式而言只有实例才能用代码表示;设计模式是比框架更小的元素,一个框架中往往含有一个或多个设计模式,框架总是针对某一特定应用领域,但同一模式却可适用于各种应用。可以说,框架是软件,而设计模式是软件的知识。
框架分为白盒框架和黑盒框架。
白盒框架:
白盒框架是基于面向对象的继承机制。之所以说是白盒框架,是因为在这种框架中,父类的方法对子类而言是可见的。子类可以通过继承或重写父类的方法来实现更具体的方法。
虽然层次结构比较清晰,但是这种方式也有其局限性,父类中的方法子类一定拥有,要么继承,要么重写,不可能存在子类中不存在的方法而在父类中存在。
通过子类化和重写方法进行扩展(使用继承);
通用设计模式:模板方法;
子类具有主要方法但对框架进行控制。
允许扩展每一个非私有方法
需要理解父类的实现
一次只进行一次扩展
通常被认为是开发者框架
examples
1
2
3
4
5
6
7
8public abstract class PrintOnScreen {
public void print() {
JFrame frame = new JFrame();
JOptionPane.showMessageDialog(frame, textToShow());
frame.dispose();
}
protected abstract String textToShow();
}1
2
3
4
5public class MyApplication extends PrintOnScreen {
protected String textToShow() {
return "printing this text on " + "screen using PrintOnScreen " + "white Box Framework";
}
}黑盒框架:
- 黑盒框架时基于委派的组合方式,是不同对象之间的组合。之所以是黑盒,是因为不用去管对象中的方法是如何实现的,只需关心对象上拥有的方法。
- 这种方式较白盒框架更为灵活,因为可以在运行时动态地传入不同对象,实现不同对象间的动态组合;而继承机制在静态编译时就已经确定好。
- 通过实现插件接口进行扩展(使用组合/委派);
- 常用设计模式:Strategy, Observer ;
- 插件加载机制加载插件并对框架进行控制。
- 允许在接口中对public方法扩展
- 只需要理解接口
- 通常提供更多的模块
- 通常被认为是终端用户框架,平台
- 黑盒框架与白盒框架之间可以相互转换,具体例子可以看一下,软件构造课程中有关黑盒框架的例子,更改上面的白盒框架为黑盒框架:
1
2
3public interface TextToShow {
String text();
}1
2
3
4
5
6public class MyTextToShow implements TextToShow {
public String text() {
return "Printing";
}
}1
2
3
4
5
6
7
8
9
10
11public final class PrintOnScreen {
TextToShow textToShow;
public PrintOnScreen(TextToShow tx) {
this.textToShow = tx;
}
public void print() {
JFrame frame = new JFrame();
JOptionPane.showMessageDialog(frame, textToShow.text());
frame.dispose();
}
}
第三节 可复用的设计模式
结构型模式:Structural patterns
适配器模式(Adapter)
装饰器模式(Decorator)
外观模式(Facade Pattern)
行为类模式:Behavioral patterns
策略模式(Strategy)
模板模式(Template method)
迭代器模式(Iterator)
第六章
第一节 可维护性的度量与构造原则
软件的维护和演化
- 定义:软件可维护性是指软件产品被修改的能力,修改包括纠正、改进或软件对环境、需求和功能规格说明变化的适应。简而言之,软件维护:修复错误、改善性能。
- 类型:纠错性(25%)、适应性(25%)、完善性(50%)、预防性(4%)
- 演化:软件演化是一个程序不断调节以满足新的软件需求过程。
- 演化的规律:软件质量下降,延续软件生命
- 软件维护和演化的目标:提高软件的适应性,延续软件生命 。
- 意义:软件维护不仅仅是运维工程师的工作,而是从设计和开发阶段就开始了 。在设计与开发阶段就要考虑将来的可维护性 ,设计方案需要“easy to change”
- 基于可维护性建设的例子:
- 模块化
- OO设计原则
- OO设计模式
- 基于状态的构造技术
- 表驱动的构造技术
- 基于语法的构造技术
可维护性的常见度量指标
- 可维护性:可轻松修改软件系统或组件,以纠正故障,提高性能或其他属性,或适应变化的环境。
- 除此之外,可维护性还有其他许多别名:可扩展性(Extensibility)、灵活性(Flexibility)、可适应性(Adaptability)、可管理性(Manageability)、支持性(Supportability)。总之,有好的可维护性就意味着容易改变,容易扩展。
- 软件可维护性的五个子特性:
- 易分析性。软件产品诊断软件中的缺陷或失效原因或识别待修改部分的能力。
- 易改变性。软件产品使指定的修改可以被实现的能力,实现包括编码、设计和文档的更改。如果软件由最终用户修改,那么易改变性可能会影响易操作性。
- 稳定性。软件产品避免由于软件修改而造成意外结果的能力。
- 易测试性。软件产品使已修改软件能被确认的能力。
- 维护性的依从性。软件产品遵循与维护性相关的标准或约定的能力。
- 一些常用的可维护性度量标准:
- 圈复杂度(CyclomaticComplexity):度量代码的结构复杂度。
- 代码行数(Lines of Code):指示代码中的大致行数。
- Halstead Volume:基于源代码中(不同)运算符和操作数的数量的合成度量。
- 可维护性指数(MI):计算介于0和100之间的索引值,表示维护代码的相对容易性。 高价值意味着更好的可维护性。
- 继承的层次数:表示扩展到类层次结构的根的类定义的数量。 等级越深,就越难理解特定方法和字段在何处被定义或重新定义。
- 类之间的耦合度:通过参数,局部变量,返回类型,方法调用,泛型或模板实例化,基类,接口实现,在外部类型上定义的字段和属性修饰来测量耦合到唯一类。
- 单元测试覆盖率:指示代码库的哪些部分被自动化单元测试覆盖。
模块化设计规范:聚合度与耦合度
- 模块化编程的含义:模块化编程是一种设计技术,它强调将程序的功能分解为独立的可互换模块,以便每个模块都包含执行所需功能的一个方面。
- 设计规范:高内聚低耦合
- 评估模块化的五个标准:
- 可分解性:将问题分解为各个可独立解决的子问题
- 可组合性:可容易的将模块组合起来形成新的系统
- 可理解性:每个子模块都可被系统设计者容易的理解
- 可持续性:小的变化将只影响一小部分模块,而不会影响整个体系结构
- 出现异常之后的保护:运行时的不正常将局限于小范围模块内
- 模块化设计的五条原则:
- 直接映射:模块的结构与现实世界中问题领域的结构保持一致
- 尽可能少的接口:模块应尽可能少的与其他模块通讯
- 尽可能小的接口:如果两个模块通讯,那么它们应交换尽可能少的信息
- 显式接口:当A与B通讯时,应明显的发生在A与B的接口之间
- 信息隐藏:经常可能发生变化的设计决策应尽可能隐藏在抽象接口后面
内聚性
- 又称块内联系。指模块的功能强度的度量,即一个模块内部各个元素彼此结合的紧密程度的度量。若一个模块内各元素(语名之间、程序段之间)联系的越紧密,则它的内聚性就越高。
- 所谓高内聚是指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一责任原则。
耦合性
- 也称块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方式及传递的信息。
- 对于低耦合,粗浅的理解是:一个完整的系统,模块与模块之间,尽可能的使其独立存在。也就是说,让每个模块,尽可能的独立完成某个特定的子功能。模块与模块之间的接口,尽量的少而简单。如果某两个模块间的关系比较复杂的话,最好首先考虑进一步的模块划分。这样有利于修改和组合。
SOLID原则
单一职责原则告诉我们实现类要职责单一;里氏替换原则告诉我们不要破坏继承体系;依赖倒置原则告诉我们要面向接口编程;接口隔离原则告诉我们在设计接口的时候要精简单一;迪米特法则告诉我们要降低耦合。而开闭原则是总纲(实现效果),它告诉我们要对扩展开放,对修改关闭。
| SRP | The Single Responsibility Principle | 单一责任原则 |
|---|---|---|
| OCP | The Open Closed Principle | 开放封闭原则 |
| LSP | The Liskov Substitution Principle | 里氏替换原则 |
| ISP | The Interface Segregation Principle | 接口分离原则 |
| DIP | The Dependency Inversion Principle | 依赖倒置原则 |
SRP 单一责任原则
- 含义:需要修改某个类的时候原因有且只有一个。换句话说就是让一个类只做一种类型责任,当这个类需要承当其他类型的责任的时候,就需要分解这个类。
- 如果一个类包含了多个责任,那么将引起不良后果:引入额外的包,占据资源;导致频繁的重新配置、部署等。
- SRP是最简单的原则,却是最难做好的原则。
- SRP的一个反例:
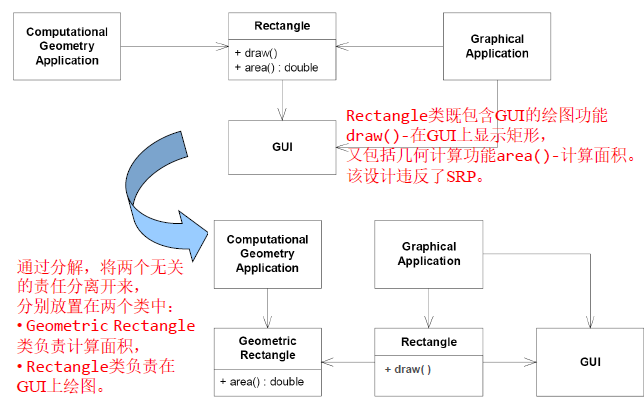
OCP 开放封闭原则
- 软件实体应该是可扩展,而不可修改的。也就是说,对扩展是开放的,而对修改是封闭的。这个原则是诸多面向对象编程原则中最抽象、最难理解的一个。
- 模块的行为应是可扩展的,从而该模块可表现出新的行为以满足需求的变化。
- 模块自身的代码是不应被修改的
- 扩展模块行为的一般途径是修改模块的内部实现
- 如果一个模块不能被修改,那么它通常被认为是具有固定的行为。
- 关键解决方案:抽象技术。 使用继承和组合来改变类的行为。
- OCP的一个反例:
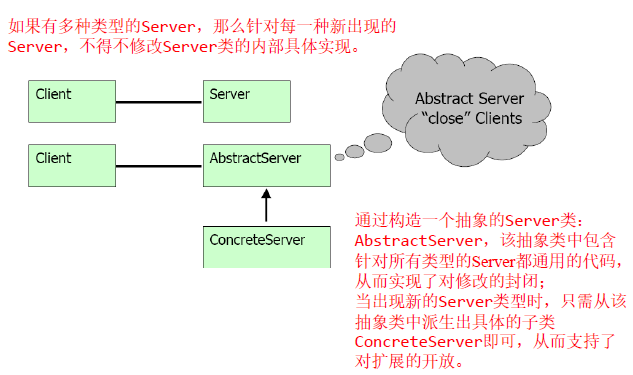
- OCP的一个例子:
1 | // Open-Close Principle - Bad ***example*** |
上面代码存在的问题:
- 不可能在不修改GraphEditor的情况下添加新的Shape
- GraphEditor和Shape之间的紧密耦合
- 不调用GraphEditor就很难测试特定的Shape
改进之后的代码:
1 | // Open-Close Principle - Good ***example*** |
LSP 里氏替换原则
- Liskov’s 替换原则意思是:”子类型必须能够替换它们的基类型。”或者换个说法:”使用基类引用的地方必须能使用继承类的对象而不必知道它。” 这个原则正是保证继承能够被正确使用的前提。通常我们都说,“优先使用组合(委托)而不是继承”或者说“只有在确定是 is-a 的关系时才能使用继承”,因为继承经常导致”紧耦合“的设计。
ISP 接口分离原则
- 含义:客户端不应依赖于它们不需要的方法。换句话说,使用多个专门的接口比使用单一的总接口总要好。
- 客户模块不应该依赖大的接口,应该裁减为小的接口给客户模块使用,以减少依赖性。如Java中一个类实现多个接口,不同的接口给不用的客户模块使用,而不是提供给客户模块一个大的接口。
- “胖”接口具有很多缺点。
- 胖接口可分解为多个小的接口;
- 不同的接口向不同的客户端提供服务;
- 客户端只访问自己所需要的端口。
- 下图展示出了这种思想:
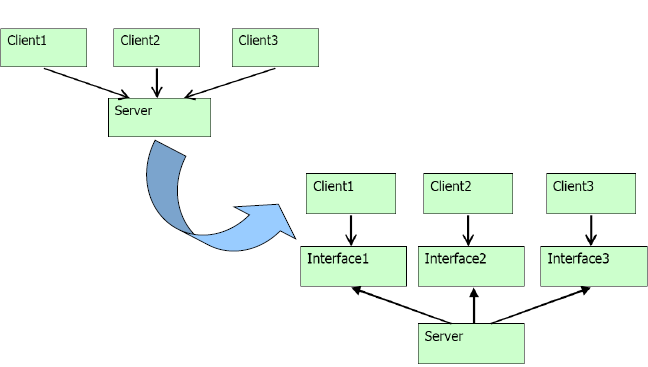
- ISP的一个反例

DIP 依赖转置原则
- 定义:
- 高层模块不应该依赖于低层模块,二者都应该依赖于抽象
- 抽象不应该依赖于细节,细节应该依赖于抽象
- 这个设计原则的亮点在于任何被DI框架注入的类很容易用mock对象进行测试和维护,因为对象创建代码集中在框架中,客户端代码也不混乱。有很多方式可以实现依赖倒置,比如像AspectJ等的AOP(Aspect Oriented programming)框架使用的字节码技术,或Spring框架使用的代理等。
- 高层模块不要依赖低层模块;
- 高层和低层模块都要依赖于抽象;
- 抽象不要依赖于具体实现;
- 具体实现要依赖于抽象;
- 抽象和接口使模块之间的依赖分离。
- 一个具体的例子:

进行抽象改进后:
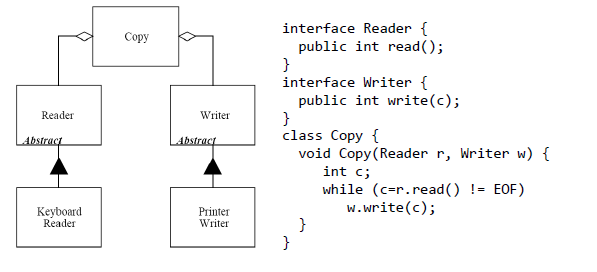
SOLID 总结
- 一个对象只承担一种责任,所有服务接口只通过它来执行这种任务。
- 程序实体,比如类和对象,向扩展行为开放,向修改行为关闭。
- 子类应该可以用来替代它所继承的类。
- 一个类对另一个类的依赖应该限制在最小化的接口上。
- 依赖抽象层(接口),而不是具体类。
第二节 可维护的设计模式
创造性模式:Creational patterns
工厂模式(Factory Pattern)
抽象工厂模式(Abstract Factory Pattern)
建造者模式(Builder Pattern)
结构化模式:Structural patterns
桥接模式(Bridge Pattern)
代理模式(Proxy Pattern)
组合模式(Composite Pattern)
行为化模式:Behavioral patterns
中介者模式(Mediator Pattern)
观察者模式(Observer Pattern)
访问者模式(Visitor Pattern)
责任链模式(Chain of Responsibility Pattern)
命令模式(Command Pattern)
第三节 面向可维护的构造技术
基于状态的构造技术
状态模式(State Pattern)
备忘录模式(Memento Pattern)
基于语法的构造技术
运用场景
- 有一类应用,从外部读取文本数据, 在应用中做进一步处理。 具体来说,读取的一个字节或字符序列可能是:
- 输入文件有特定格式,程序需读取文件并从中抽取正确的内容。
- 从网络上传输过来的消息,遵循特定的协议。
- 用户在命令行输入的指令,遵顼特定的格式。
- 内存中存储的字符串,也有格式需要。
对于这些类型的序列,语法的概念是设计的一个好选择:
- 使用grammar判断字符串是否合法,并解析成程序里使用的数据结构 。
- 正则表达式
- 通常是递归的数据结构 。
语法成分
terminals 终止节点、叶节点
nonterminal 非终止节点(遵循特定规则,利用操作符、终止节点和其他非终止节点,构造新的字符串)
语法中的操作符
- 三个基本语法的操作符:
- 连接,不是通过一个符号,而是一个空间:
x ::= y z //x等价于y后跟一个z
- 重复,以*表示:
x ::= y* // x等价于0个或更多个y
- 联合,也称为交替,如图所示 | :
x ::= y | z //x等价于一个y或者一个z
- 连接,不是通过一个符号,而是一个空间:
- 三个基本操作符的组合:
- 可选(0或1次出现),由
?表示:x ::= y? //x等价于一个y或者一个空串
- 出现1次或多次:以
+表示:x ::= y+ //x等价于一个或者更多个y, 等价于 x ::= y y*
- 字符类
[…],表示长度的字符类,包含方括号中列出的任何字符的1个字符串:x ::= [abc] //等价于 x ::= 'a' | 'b' | 'c'
- 否定的字符类
[^…],表示长度,包含未在括号中列出的任何字符的1个字符串:x ::= [^abc] //等价于 x ::= 'd' | 'e' | 'f' | ... (all other characters in Unicode)
- 可选(0或1次出现),由
- 例子:
x ::= (y z | a b)* //an x is zero or more y z or a b pairsm ::= a (b|c) d //an m is a, followed by either b or c, followed by d
Markdown 和 HTML的语法

正则语法与正则表达式
- 正则语法:简化之后可以表达为一个产生式而不包含任何非终止节点。
- 正则语法示例:
1 | //Rugular! |
- 在Java中使用正则表达式
- 适用场合:我们用正则表达式匹配字符串(例如 String.split , String.matches , java.util.regex.Pattern)